 最近被一位資深的資訊界前輩問到說,當資料庫查詢資料不是使用你建立的索引時,有沒有什麼解決方式可以改善此類的問題,當時我的回答印象中是先看建立的索引是否有誤或確認有沒有漏掉某些該包含的欄位,對於這樣的回應這位前輩看起來是不太買單XD,經過一番討論後,大概了解到他想聽到的解法為直接在 SQL 查詢語句裡加入指定要使用的索引。嗯...到這邊,我先承認其實我以前還真的沒想到過可以使用這種方式來處理這類問題,因此就趁這個機會來稍微研究一下這個問題背後可能的原因及解決方式,但先說在前,本人對 SQL 並無太多深入的研究,這邊只算是紀錄個人對該問題的處理心得,所以內容不一定正確且適用每個場景,如果有錯的地方,還請各位前輩們高抬貴手給予指正。
最近被一位資深的資訊界前輩問到說,當資料庫查詢資料不是使用你建立的索引時,有沒有什麼解決方式可以改善此類的問題,當時我的回答印象中是先看建立的索引是否有誤或確認有沒有漏掉某些該包含的欄位,對於這樣的回應這位前輩看起來是不太買單XD,經過一番討論後,大概了解到他想聽到的解法為直接在 SQL 查詢語句裡加入指定要使用的索引。嗯...到這邊,我先承認其實我以前還真的沒想到過可以使用這種方式來處理這類問題,因此就趁這個機會來稍微研究一下這個問題背後可能的原因及解決方式,但先說在前,本人對 SQL 並無太多深入的研究,這邊只算是紀錄個人對該問題的處理心得,所以內容不一定正確且適用每個場景,如果有錯的地方,還請各位前輩們高抬貴手給予指正。
SQL 在做查詢時,資料庫關聯引擎(Database Relational Engine)會先透過查詢優化器(Query Optimizer)對指令做分析產生執行計畫(Execution Plan),之後再根據該執行計畫從表裡取回資料,產生的執行計畫通常就是資料庫認為最有效率(快)找到目標資料的方式,有估計(Estimated Plan)及實際(Actual Plan)兩種模式,本篇皆會以實際為主。另外執行計畫裡有以下幾種找資料的方式,分別為
**Table Scan:**
當資料表(Table)無建立任何索引時,資料表就屬於 Heap Table,新資料在儲存時並不會依照寫入的先後順序或特定排序乖乖存入表裡,例如:**當要查詢資料時,資料庫引擎就必須從頭到尾對表裡所有的資料做掃描比對**,直到滿足需要的筆數後再返回,算是最沒效率的搜尋方式。基本上,現在自己也很少遇到沒有建立任何索引的資料表(太幸福?),故本篇不討論此種搜尋方式。
**Clustered Index Scan:**
當資料表有建立叢集索引(Clustered Index)時,資料表就會從 Heap Table 轉變成 Clustered Table,新資料在儲存時就會依照叢集索引的排序依序存入表裡,SQL Server 通常會將主鍵(Primary Key)預設為叢集索引,每張表最多也只能有一個叢集索引。**當搜尋資料時,資料庫引擎認為當下沒有其它適用的索引(包含叢集索引自己)可加速查詢時,就會從頭到尾掃描表裡所有的叢集索引並取回相符合的筆數**,類似於 **Table Scan**。
**Clustered Index Seek:**
若資料表含有叢集索引且**查詢條件具有該索引的第一個欄位,然後當下無其它更適用的非叢集索引**可加速查詢時,資料庫引擎就會直接定位到該索引適當的位置並根據所需筆數將符合條件的資料取回。
**Non-clustered Index Scan & Seek:**
叢集索引以外的索引都可歸類為非叢集索引(Non-clustered Index),每張表裡可以建立多個非叢集索引。**當查詢條件具有該類索引的第一個欄位且查詢優化器判斷使用該類索引可最快找到目標資料時**,就會採用之並將符合條件的資料逐筆取回,而資料庫引擎也會視所需筆數來決定該以 Scan 還是 Seek 方式進行搜尋。其中,若有查詢的欄位不包含在該類索引裡,則還會用到 *Key Lookup* 或 *RID Lookup* 這兩種查找資料的方式。
**RID(Row ID) Lookup:**
當資料表**沒有建立叢集索引**的狀況下,使用非叢集索引查找資料且返回的查詢欄位有部分不在該索引上時,就會使用 Row ID 來進一步查找這些未包含的欄位。
**Key Lookup:**
當資料表**有建立叢集索引**的狀況下,使用非叢集索引查找資料且返回的查詢欄位有部分不在該索引上時,就會使用叢集索引來進一步查找這些未包含的欄位。由於使用 Lookup 會消耗較多的磁碟 I∕O 及 CPU,因此執行計畫如果有出現 *Key Lookup* 或 *RID Lookup* 的查找方式時,通常都會是效能調校的首要重點。
一般來說,採用 **Seek** 會比 **Scan** 來的還有效率,下面為簡易的示意圖(假設要找出所有 2 的資料),可看出使用 **Scan** 方式必須從頭到尾將資料都掃過一次才能確保篩選出所有符合的資料,而使用 **Seek** 方式則是資料庫引擎透過事先建立好的索引將已排序且符合條件的資料篩選出來即可,不需要整張表都掃過一遍

但當資料不多或是返回筆數趨近於表裡全部的總筆數時,採用 **Scan** 方式就有可能比 **Seek** 來得快,關於這點,本人目前還沒有太多深入的研究,反正資料庫引擎會先幫我判斷就對了( ̄▽ ̄)
##**準備測試用資料** **1\. 建立測試用資料表** 這次測試資料的準備參考了[該篇問題](https://dba.stackexchange.com/questions/292020/sql-server-not-using-index)提供的方式 ```sql // 遊戲房間 CREATE TABLE GameRoom( [Id] [bigint] IDENTITY(1,1) NOT NULL PRIMARY KEY, [Name] [nvarchar](100) NOT NULL ) GO // 遊戲參與者 CREATE TABLE Competitor( [Id] [bigint] IDENTITY(1,1) NOT NULL PRIMARY KEY, [GameRoomId] [bigint] NOT NULL, [Name] [nvarchar](100) NOT NULL, [BetNumber] [int] NOT NULL, [Level] [nvarchar](50) NOT NULL ) GO ALTER TABLE Competitor WITH CHECK ADD CONSTRAINT FK_Competitor_GameRoom_GameRoomId FOREIGN KEY(GameRoomId) REFERENCES GameRoom ([Id]) GO ALTER TABLE Competitor CHECK CONSTRAINT FK_Competitor_GameRoom_GameRoomId GO // 開獎號碼 CREATE TABLE Lottery( [Id] [bigint] IDENTITY(1,1) NOT NULL PRIMARY KEY, [GameRoomId] [bigint] NOT NULL, [Number] [int] NOT NULL, [Type] [nvarchar](50) NOT NULL DEFAULT ('Normal'), [DrawOn] [datetime2](7) NOT NULL ) GO ALTER TABLE Lottery WITH CHECK ADD CONSTRAINT FK_Lottery_GameRoom_GameRoomId FOREIGN KEY(GameRoomId) REFERENCES GameRoom ([Id]) GO ALTER TABLE Lottery CHECK CONSTRAINT FK_Lottery_GameRoom_GameRoomId GO ``` 資料表之間的結構與關聯如下圖  **2\. 產生測試資料** ```sql Declare @Count int = 0 Declare @RoomId int = 0 Declare @CompetitorId int = 0 SET NOCOUNT ON While(@Count < 50000) Begin Set @Count = @Count+1 Insert Into GameRoom(Name) Select 'Room ' + CONVERT(nvarchar(10), @Count) Set @RoomId = SCOPE_IDENTITY() Set @CompetitorId = FLOOR(RAND()*(10)+1) Declare @BetNumber int= FLOOR(RAND()*(50)+1) Insert Into Competitor(GameRoomId, Name, [BetNumber], Level) Select @RoomId, 'Competitor_' + CONVERT(nvarchar(10), @CompetitorId), FLOOR(RAND()*(50)+1), 'Guest' Union Select @RoomId, 'Competitor_' + CONVERT(nvarchar(10), @CompetitorId+1), FLOOR(RAND()*(50)+1), 'Guest' Union Select @RoomId, 'Competitor_' + CONVERT(nvarchar(10), @CompetitorId+2), FLOOR(RAND()*(50)+1), 'VIP' Declare @CurrentLottery int= 0 While(@CurrentLottery < 5) Begin Insert Into Lottery(GameRoomId, [Number], [Type], DrawOn) Select @RoomId, FLOOR(RAND()*(50)+1), case @CurrentLottery % 5 when 0 then 'Special' else 'Normal' end, SYSDATETIME() Set @CurrentLottery = @CurrentLottery + 1 End End ``` 上面共會產生 50000 個遊戲房間,每間房會有 2 個一般玩家和 1 個 VIP 玩家,然後每間房固定會開出 4 個普通號碼和 1 個特別號碼(開出的號碼可重複),所以每張表的資料總筆數如下: - GameRoom:50000 - Competitor:150000(100000 個 Guest + 50000 個 VIP) - Lottery:250000(200000 個普通號碼 + 50000 個特別號碼)
##**開始測試** 這邊我使用了 [Azure Data Studio](https://docs.microsoft.com/en-us/sql/azure-data-studio/download-azure-data-studio) 來觀察資料庫引擎使用的執行計畫,以當前 Competitor 資料表裡只有叢集索引來說,查詢前 30000 個 **Level** 欄位為 `VIP` 的資料,產生的執行計畫會如下圖所示  若把游標移到圖示上方,則會出現更詳細的訊息  **案例一、善用覆蓋索引(Covering Index)** 新增以下非叢集索引 ```sql Create Index IX_Level ON Competitor([Level]) ``` 然後查詢 Competitor 資料表前 30000 個 **Level** 為 `VIP` 的資料,且返回的欄位需包含 **Id** 及 **Level**,產生的執行計畫如下  剛建立的索引確實有被用到,接著測試在相同條件下,希望返回全部的欄位,產生的執行計畫如下 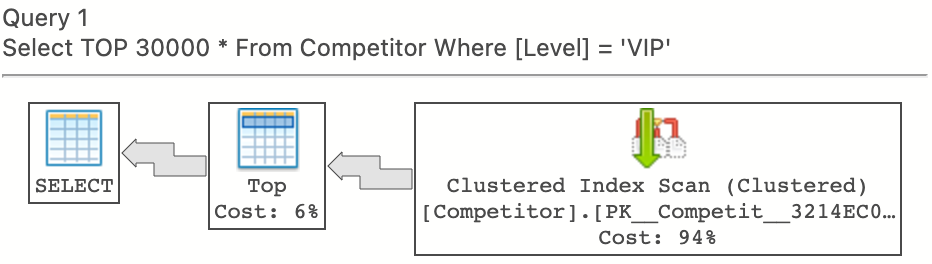 會發現資料庫並沒有用到我們剛建立的索引,反而使用叢集索引掃描(Clustered Index Scan)的方式來尋找資料,原因在於 **IX_Level** 該索引上只有包含 **Id** 及 **Level** 兩個欄位的資料(每個非叢集索引本身都會存放叢集索引的主欄位,即 **Id**),因此若要返回其它欄位,則就需要再用到 *Key Lookup* 的查找方式撈出剩餘欄位的資料。但這邊執行計畫卻是使用掃描的方式來查找資料,猜想應該是經過查詢優化器計算後,判斷使用`Clustered Index Scan`會比我預期用`Non-clustered Index Seek + Key Lookup`的方式還要來的有效,不信邪,直接指定建立的索引再跑一次看看  這邊出現了新增索引的建議,等下說明,先比較`Clustered Index Scan`與`Non-clustered Index Seek + Key Lookup`兩者的效能差異  以總作業成本(Estimated Operator Cost)來看,確實使用`Clustered Index Scan`的方式會較有效率,但我們希望執行計畫是採用我們建立的索引,要改善此問題,就會用到覆蓋索引,也就是剛才資料庫引擎建議我們建立的索引,是一種非叢集索引的延伸。方式為在建立索引時加上 Include 語法,將索引以外需要返回的欄位一併包含進來(不存在當前索引子頁層上,這邊暫不討論有關子頁層的原理),如下所示 ```sql Create Index IX_Level_Covering ON Competitor([Level]) Include (GameRoomId, Name, BetNumber) ``` 然後試著在執行一次,產生的執行計畫如下  這次果然不負眾望使用了 **IX\_Level\_Covering** 索引來查找資料,接著用下圖比較一下`Clustered Index Scan`與`Non-clustered Index Seek`的效能差異 
由上表可看出,建立正確的索引除了可避免資料庫引擎使用非預期的索引外,還能提高資料庫的執行效率,減少多餘的性能消耗。
**案例二、索引欄位順序對效能的影響**
新增以下非叢集索引
```sql
// 建立一個覆蓋索引且第一個欄位使用 Number
Create Index IX_Number_Type ON Lottery([Number], [Type]) Include ([GameRoomId], DrawOn)
```
然後比較以下兩種查詢方式的執行計畫,如
```sql
Select Top 25000 * From [Lottery] Where [Number] > 20 AND [Type] = 'Special'
Select Top 25000 * From [Lottery] Where [Type] = 'Special'
```

從上圖的結果可觀察到,查詢條件必須涵蓋索引的第一個欄位(順序不影響)才會被資料庫引擎使用。接著再繼續細看 **IX\_Number\_Type** 的執行計畫

這邊發現了一個問題,目標資料量為 25000 筆,所以預期資料庫引擎也應該只需要讀取差不多的筆數即可,但實際上,卻讀取(Number of Rows Read)了 124767 這麼多筆資料才完成這次的作業,顯然該索引對這次的查詢幫助並不大,因此這邊將索引修改如下
```sql
// 1. 刪除索引 IX_Number_Type
Drop Index Lottery.IX_Number_Type
// 2. 建立新的覆蓋索引且第一個欄位改使用 Type
Create Index IX_Type_Number ON Lottery([Type], [Number]) Include ([GameRoomId], DrawOn)
```
再重新執行一次查詢並查看詳細的執行計畫,如下

Perfect!不論是實際讀取筆數或是估計作業成本(包含 I/O、CPU)的消耗都有明顯的降低,故可推斷索引內之欄位順序是會影響實際查詢的效能,所以在建立索引時,欄位順序的選擇也是非常重要的。
補充:這邊算是用圖幫自己整理一下該案例的觀念,下圖分別為使用 **IX\_Number\_Type** 及 **IX\_Type\_Number** 兩種索引產生的資料排序方式,假設我打算找出前 5 筆號碼需大於 1 的特別號(Special),前者需要讀到第 10 筆資料才能完成該次作業,而後者只需要讀到第 5 筆即可,後者樂勝。  **案例三、表連接(Join)與索引的關係** 此案例為參考[該篇問題](https://dba.stackexchange.com/questions/292020/sql-server-not-using-index)發問者的疑問,也算是案例二的延伸,一開始先建立兩個覆蓋索引,分別為 ```sql // 在 Competitor 表上對 Level 欄位建立一個覆蓋索引 Create Index IX_Level ON Competitor([Level]) Include (GameRoomId, Name, BetNumber) // 在 Lottery 表上對 GameRoomId 及 Type 欄位建立一個覆蓋索引,第一個欄位使用 GameRoomId Create Index IX_GameRoomId_Type ON Lottery([GameRoomId], [Type]) Include ([Number], DrawOn) ``` 接著想要查詢出每間房身分為 VIP 的參與者之下注號碼及該間房開出的特別號碼,語法及產生的執行計畫如下 ```sql Select c.Id AS CompetitorId, c.Name, c.BetNumber, l.Number AS LotteryNumber From Competitor c Inner Join [Lottery] l ON c.GameRoomId = l.GameRoomId AND l.Type='Special' Where c.[Level] = 'VIP' ```  首先,可以看到兩個索引都有被確實使用到,不過 IX\_GameRoomId\_Type 並非用原先預期的 **Seek** 方式來搜尋資料,而是以 **Scan** 的方式,然後資料庫引擎也提示了兩則新增索引的建議,分別為: 1. 在 Lottery 表上,只針對 **Type** 建立覆蓋索引就好 2. 在 Competitor 表上對 **GameRoomId** 和 **Level** 建立新的覆蓋索引 在看到建議並自己思考後,確實在 Lottery 表上選擇以 **Type** 當做非叢集索引的第一欄位應該能改善查找的方式。講一下自己的思路供參考,Lottery 表上的索引 IX\_GameRoomId\_Type 是先對 **GameRoomId** 做排序後才再對 **Type** 做排序,因此當以 Competitor 做主表,而每間房又都有一位 VIP 時,以 IX\_GameRoomId\_Type 的排序方式來看,幾乎就需要讀過整個索引才有辦法完成此次查詢,下面為簡易的示意圖  若採用建議,使用以 **Type** 為主的覆蓋索引,則示意圖會變更為  不囉嗦,直接將 IX\_GameRoomId\_Type 換掉,然後再執行相同的查詢語法並觀察新產生的執行計畫 ```sql // 1. 刪除索引 IX_GameRoomId_Type Drop Index Lottery.IX_GameRoomId_Type // 2. 建立以 Type 為主的覆蓋索引 Create Index IX_Type ON Lottery([Type]) Include (GameRoomId, [Number], DrawOn) ```  使用新的索引後,查找方式已經從 **Scan** 轉為 **Seek**,以下為 IX\_GameRoomId\_Type 及 IX_Type 兩者的比較 
由比較表可看出,使用 IX_Type 來查找資料確實可大幅減少效能的消耗,再次驗證索引欄位的順序很重要!
除了對 **Type** 建立專用的覆蓋索引外,資料庫引擎也給出了另一個優化建議,就是新增一個 **GameRoomId** 及 **Level** 兩個欄位組合的覆蓋索引,關於這點,我是有點疑惑,理由在於該次查詢 Competitor 表裡已經充分使用了 IX_Level 來搜尋資料,實在想不出建立新索引的好處,所以就抱著可能會有什麼新觀念要來給我衝擊一發的心態上嘗試看看,就先直接把它給建起來,並重跑一次查詢,如下所示(IX\_Level 保留) ```sql // 建立以 GameRoomId 和 Level 組合的覆蓋索引 Create Index IX_GameRoomId_Level ON Competitor(GameRoomId,[Level]) Include (Name, BetNumber) // 清除查詢 Cache DBCC FREEPROCCACHE // 執行查詢 Select c.Id AS CompetitorId, c.Name, c.BetNumber, l.Number AS LotteryNumber From Competitor c Inner Join [Lottery] l ON c.GameRoomId = l.GameRoomId AND l.Type='Special' Where c.[Level] = 'VIP' ```  疑...這結果怎麼似曾相似,若不是因為少了新增索引的建議,我還真的會懷疑是不是 IX_GameRoomId\_Level 建立失敗。初步來看,查詢優化器認為使用 IX\_Level 搜尋資料的效率會優於 IX\_GameRoomId\_Level,為了追根究柢,這邊我直接指定 Competitor 使用 IX\_GameRoomId\_Level 來查找資料,順便比較一下兩種索引的效能開銷 ```sql // 指定 Competitor 表使用索引 IX_GameRoomId_Level Select c.Id AS CompetitorId, c.Name, c.BetNumber, l.Number AS LotteryNumber From Competitor c With(Index(IX_GameRoomId_Level)) Inner Join [Lottery] l ON c.GameRoomId = l.GameRoomId AND l.Type='Special' Where c.[Level] = 'VIP' ``` 
由上面的圖表結果可看出選擇使用 IX\_Level 確實效率較好,這不禁讓我開始有點質疑資料庫引擎的建議是不是需視情況採納,也藉此順便警惕自己很多觀念盡量還是親手跑過一次才不會有一知半解的現象。
##**結論** 經過以上一連串針對資料庫引擎沒有使用預先建立的索引案例測試,整理出以下幾個結論 ● 適時建立並善用覆蓋索引(Covering Index) ● 查詢條件需包含預期索引的第一個欄位 ● 索引內的欄位順序很重要 ● 直接指定要使用的索引未必會比資料庫引擎分析後使用的索引要來的好 ● 資料庫引擎給出的建議可參考但未必較好 ● 估計和實際執行計畫(Execution Plan & Actual Plan)兩者可能會有差異 另外,這篇心得為求簡單好懂(謎之音:疑...有嗎?)及避免模糊焦點,所以偏離主題太多的觀念就先省略了,例如索引使用了 B+Tree 的資料結構來幫助查詢資料、子葉層(Leaf Page)、子葉節點(Leaf Node)等代表意義,這些網路上的教學不勝枚舉,有興趣都可自行搜尋相關資源學習。
##參考資料 [\[黑暗執行緒\] Index Scan vs Index Seek](https://blog.darkthread.net/blog/index-scan-vs-seek) [\[Jeffcky\] 聚焦移除 Bookmark Lookup、RID Lookup、Key Lookup 提高 SQL Server 查询性能](https://www.cnblogs.com/CreateMyself/p/6117352.html) [\[Stack Exchange\] SQL Server not Using Index](https://dba.stackexchange.com/questions/292020/sql-server-not-using-index) [\[SQL Espresso\] What's a Key Lookup](https://www.sqlshack.com/how-to-analyze-sql-execution-plan-graphical-components/) [\[SQL Shack\] How to Analyze SQL Execution Plan Graphical Components](https://www.sqlshack.com/how-to-analyze-sql-execution-plan-graphical-components/) [\[SQL Shack\] SQL Server Execution Plan Operators – Part 1](https://www.sqlshack.com/sql-server-execution-plan-operators-part-1/)
##**準備測試用資料** **1\. 建立測試用資料表** 這次測試資料的準備參考了[該篇問題](https://dba.stackexchange.com/questions/292020/sql-server-not-using-index)提供的方式 ```sql // 遊戲房間 CREATE TABLE GameRoom( [Id] [bigint] IDENTITY(1,1) NOT NULL PRIMARY KEY, [Name] [nvarchar](100) NOT NULL ) GO // 遊戲參與者 CREATE TABLE Competitor( [Id] [bigint] IDENTITY(1,1) NOT NULL PRIMARY KEY, [GameRoomId] [bigint] NOT NULL, [Name] [nvarchar](100) NOT NULL, [BetNumber] [int] NOT NULL, [Level] [nvarchar](50) NOT NULL ) GO ALTER TABLE Competitor WITH CHECK ADD CONSTRAINT FK_Competitor_GameRoom_GameRoomId FOREIGN KEY(GameRoomId) REFERENCES GameRoom ([Id]) GO ALTER TABLE Competitor CHECK CONSTRAINT FK_Competitor_GameRoom_GameRoomId GO // 開獎號碼 CREATE TABLE Lottery( [Id] [bigint] IDENTITY(1,1) NOT NULL PRIMARY KEY, [GameRoomId] [bigint] NOT NULL, [Number] [int] NOT NULL, [Type] [nvarchar](50) NOT NULL DEFAULT ('Normal'), [DrawOn] [datetime2](7) NOT NULL ) GO ALTER TABLE Lottery WITH CHECK ADD CONSTRAINT FK_Lottery_GameRoom_GameRoomId FOREIGN KEY(GameRoomId) REFERENCES GameRoom ([Id]) GO ALTER TABLE Lottery CHECK CONSTRAINT FK_Lottery_GameRoom_GameRoomId GO ``` 資料表之間的結構與關聯如下圖  **2\. 產生測試資料** ```sql Declare @Count int = 0 Declare @RoomId int = 0 Declare @CompetitorId int = 0 SET NOCOUNT ON While(@Count < 50000) Begin Set @Count = @Count+1 Insert Into GameRoom(Name) Select 'Room ' + CONVERT(nvarchar(10), @Count) Set @RoomId = SCOPE_IDENTITY() Set @CompetitorId = FLOOR(RAND()*(10)+1) Declare @BetNumber int= FLOOR(RAND()*(50)+1) Insert Into Competitor(GameRoomId, Name, [BetNumber], Level) Select @RoomId, 'Competitor_' + CONVERT(nvarchar(10), @CompetitorId), FLOOR(RAND()*(50)+1), 'Guest' Union Select @RoomId, 'Competitor_' + CONVERT(nvarchar(10), @CompetitorId+1), FLOOR(RAND()*(50)+1), 'Guest' Union Select @RoomId, 'Competitor_' + CONVERT(nvarchar(10), @CompetitorId+2), FLOOR(RAND()*(50)+1), 'VIP' Declare @CurrentLottery int= 0 While(@CurrentLottery < 5) Begin Insert Into Lottery(GameRoomId, [Number], [Type], DrawOn) Select @RoomId, FLOOR(RAND()*(50)+1), case @CurrentLottery % 5 when 0 then 'Special' else 'Normal' end, SYSDATETIME() Set @CurrentLottery = @CurrentLottery + 1 End End ``` 上面共會產生 50000 個遊戲房間,每間房會有 2 個一般玩家和 1 個 VIP 玩家,然後每間房固定會開出 4 個普通號碼和 1 個特別號碼(開出的號碼可重複),所以每張表的資料總筆數如下: - GameRoom:50000 - Competitor:150000(100000 個 Guest + 50000 個 VIP) - Lottery:250000(200000 個普通號碼 + 50000 個特別號碼)
##**開始測試** 這邊我使用了 [Azure Data Studio](https://docs.microsoft.com/en-us/sql/azure-data-studio/download-azure-data-studio) 來觀察資料庫引擎使用的執行計畫,以當前 Competitor 資料表裡只有叢集索引來說,查詢前 30000 個 **Level** 欄位為 `VIP` 的資料,產生的執行計畫會如下圖所示  若把游標移到圖示上方,則會出現更詳細的訊息  **案例一、善用覆蓋索引(Covering Index)** 新增以下非叢集索引 ```sql Create Index IX_Level ON Competitor([Level]) ``` 然後查詢 Competitor 資料表前 30000 個 **Level** 為 `VIP` 的資料,且返回的欄位需包含 **Id** 及 **Level**,產生的執行計畫如下  剛建立的索引確實有被用到,接著測試在相同條件下,希望返回全部的欄位,產生的執行計畫如下  會發現資料庫並沒有用到我們剛建立的索引,反而使用叢集索引掃描(Clustered Index Scan)的方式來尋找資料,原因在於 **IX_Level** 該索引上只有包含 **Id** 及 **Level** 兩個欄位的資料(每個非叢集索引本身都會存放叢集索引的主欄位,即 **Id**),因此若要返回其它欄位,則就需要再用到 *Key Lookup* 的查找方式撈出剩餘欄位的資料。但這邊執行計畫卻是使用掃描的方式來查找資料,猜想應該是經過查詢優化器計算後,判斷使用`Clustered Index Scan`會比我預期用`Non-clustered Index Seek + Key Lookup`的方式還要來的有效,不信邪,直接指定建立的索引再跑一次看看  這邊出現了新增索引的建議,等下說明,先比較`Clustered Index Scan`與`Non-clustered Index Seek + Key Lookup`兩者的效能差異  以總作業成本(Estimated Operator Cost)來看,確實使用`Clustered Index Scan`的方式會較有效率,但我們希望執行計畫是採用我們建立的索引,要改善此問題,就會用到覆蓋索引,也就是剛才資料庫引擎建議我們建立的索引,是一種非叢集索引的延伸。方式為在建立索引時加上 Include 語法,將索引以外需要返回的欄位一併包含進來(不存在當前索引子頁層上,這邊暫不討論有關子頁層的原理),如下所示 ```sql Create Index IX_Level_Covering ON Competitor([Level]) Include (GameRoomId, Name, BetNumber) ``` 然後試著在執行一次,產生的執行計畫如下  這次果然不負眾望使用了 **IX\_Level\_Covering** 索引來查找資料,接著用下圖比較一下`Clustered Index Scan`與`Non-clustered Index Seek`的效能差異 
| Clustered Index Scan | Non-clustered Index Seek | |
|---|---|---|
| 實際讀取筆數(Number of Rows Read) | 90000 | 30000 |
| 估計作業成本(Estimated Operator Cost) | 0.791612 | 0.218946 |
| 估計 I/O 成本(Estimated I/O Cost) | 1.152010 | 0.307569 |
| 估計 CPU 成本(Estimated CPU Cost) | 0.165157 | 0.055157 |
| 估計子樹成本(Estimated Subtree Cost) | 0.791612 | 0.218946 |
| 已排序(Ordered) | 否 | 是 |
補充:這邊算是用圖幫自己整理一下該案例的觀念,下圖分別為使用 **IX\_Number\_Type** 及 **IX\_Type\_Number** 兩種索引產生的資料排序方式,假設我打算找出前 5 筆號碼需大於 1 的特別號(Special),前者需要讀到第 10 筆資料才能完成該次作業,而後者只需要讀到第 5 筆即可,後者樂勝。  **案例三、表連接(Join)與索引的關係** 此案例為參考[該篇問題](https://dba.stackexchange.com/questions/292020/sql-server-not-using-index)發問者的疑問,也算是案例二的延伸,一開始先建立兩個覆蓋索引,分別為 ```sql // 在 Competitor 表上對 Level 欄位建立一個覆蓋索引 Create Index IX_Level ON Competitor([Level]) Include (GameRoomId, Name, BetNumber) // 在 Lottery 表上對 GameRoomId 及 Type 欄位建立一個覆蓋索引,第一個欄位使用 GameRoomId Create Index IX_GameRoomId_Type ON Lottery([GameRoomId], [Type]) Include ([Number], DrawOn) ``` 接著想要查詢出每間房身分為 VIP 的參與者之下注號碼及該間房開出的特別號碼,語法及產生的執行計畫如下 ```sql Select c.Id AS CompetitorId, c.Name, c.BetNumber, l.Number AS LotteryNumber From Competitor c Inner Join [Lottery] l ON c.GameRoomId = l.GameRoomId AND l.Type='Special' Where c.[Level] = 'VIP' ```  首先,可以看到兩個索引都有被確實使用到,不過 IX\_GameRoomId\_Type 並非用原先預期的 **Seek** 方式來搜尋資料,而是以 **Scan** 的方式,然後資料庫引擎也提示了兩則新增索引的建議,分別為: 1. 在 Lottery 表上,只針對 **Type** 建立覆蓋索引就好 2. 在 Competitor 表上對 **GameRoomId** 和 **Level** 建立新的覆蓋索引 在看到建議並自己思考後,確實在 Lottery 表上選擇以 **Type** 當做非叢集索引的第一欄位應該能改善查找的方式。講一下自己的思路供參考,Lottery 表上的索引 IX\_GameRoomId\_Type 是先對 **GameRoomId** 做排序後才再對 **Type** 做排序,因此當以 Competitor 做主表,而每間房又都有一位 VIP 時,以 IX\_GameRoomId\_Type 的排序方式來看,幾乎就需要讀過整個索引才有辦法完成此次查詢,下面為簡易的示意圖  若採用建議,使用以 **Type** 為主的覆蓋索引,則示意圖會變更為  不囉嗦,直接將 IX\_GameRoomId\_Type 換掉,然後再執行相同的查詢語法並觀察新產生的執行計畫 ```sql // 1. 刪除索引 IX_GameRoomId_Type Drop Index Lottery.IX_GameRoomId_Type // 2. 建立以 Type 為主的覆蓋索引 Create Index IX_Type ON Lottery([Type]) Include (GameRoomId, [Number], DrawOn) ```  使用新的索引後,查找方式已經從 **Scan** 轉為 **Seek**,以下為 IX\_GameRoomId\_Type 及 IX_Type 兩者的比較 
| IX_GameRoomId_Type | IX_Type | |
|---|---|---|
| 實際讀取筆數(Number of Rows Read) | 250000 | 50000 |
| 估計作業成本(Estimated Operator Cost) | 1.43532 | 0.289393 |
| 估計 I/O 成本(Estimated I/O Cost) | 1.16016 | 0.234236 |
| 估計 CPU 成本(Estimated CPU Cost) | 0.275157 | 0.055157 |
| 估計子樹成本(Estimated Subtree Cost) | 1.43532 | 0.289393 |
| 已排序(Ordered) | 否 | 是 |
除了對 **Type** 建立專用的覆蓋索引外,資料庫引擎也給出了另一個優化建議,就是新增一個 **GameRoomId** 及 **Level** 兩個欄位組合的覆蓋索引,關於這點,我是有點疑惑,理由在於該次查詢 Competitor 表裡已經充分使用了 IX_Level 來搜尋資料,實在想不出建立新索引的好處,所以就抱著可能會有什麼新觀念要來給我衝擊一發的心態上嘗試看看,就先直接把它給建起來,並重跑一次查詢,如下所示(IX\_Level 保留) ```sql // 建立以 GameRoomId 和 Level 組合的覆蓋索引 Create Index IX_GameRoomId_Level ON Competitor(GameRoomId,[Level]) Include (Name, BetNumber) // 清除查詢 Cache DBCC FREEPROCCACHE // 執行查詢 Select c.Id AS CompetitorId, c.Name, c.BetNumber, l.Number AS LotteryNumber From Competitor c Inner Join [Lottery] l ON c.GameRoomId = l.GameRoomId AND l.Type='Special' Where c.[Level] = 'VIP' ```  疑...這結果怎麼似曾相似,若不是因為少了新增索引的建議,我還真的會懷疑是不是 IX_GameRoomId\_Level 建立失敗。初步來看,查詢優化器認為使用 IX\_Level 搜尋資料的效率會優於 IX\_GameRoomId\_Level,為了追根究柢,這邊我直接指定 Competitor 使用 IX\_GameRoomId\_Level 來查找資料,順便比較一下兩種索引的效能開銷 ```sql // 指定 Competitor 表使用索引 IX_GameRoomId_Level Select c.Id AS CompetitorId, c.Name, c.BetNumber, l.Number AS LotteryNumber From Competitor c With(Index(IX_GameRoomId_Level)) Inner Join [Lottery] l ON c.GameRoomId = l.GameRoomId AND l.Type='Special' Where c.[Level] = 'VIP' ``` 
| IX_Level | IX_GameRoomId_Level | |
|---|---|---|
| 實際讀取筆數(Number of Rows Read) | 50000 | 150000 |
| 估計作業成本(Estimated Operator Cost) | 0.35606 | 1.06384 |
| 估計 I/O 成本(Estimated I/O Cost) | 0.300903 | 0.898681 |
| 估計 CPU 成本(Estimated CPU Cost) | 0.055157 | 0.165157 |
| 估計子樹成本(Estimated Subtree Cost) | 0.35606 | 1.06384 |
| 已排序(Ordered) | 是 | 否 |
##**結論** 經過以上一連串針對資料庫引擎沒有使用預先建立的索引案例測試,整理出以下幾個結論 ● 適時建立並善用覆蓋索引(Covering Index) ● 查詢條件需包含預期索引的第一個欄位 ● 索引內的欄位順序很重要 ● 直接指定要使用的索引未必會比資料庫引擎分析後使用的索引要來的好 ● 資料庫引擎給出的建議可參考但未必較好 ● 估計和實際執行計畫(Execution Plan & Actual Plan)兩者可能會有差異 另外,這篇心得為求簡單好懂
##參考資料 [\[黑暗執行緒\] Index Scan vs Index Seek](https://blog.darkthread.net/blog/index-scan-vs-seek) [\[Jeffcky\] 聚焦移除 Bookmark Lookup、RID Lookup、Key Lookup 提高 SQL Server 查询性能](https://www.cnblogs.com/CreateMyself/p/6117352.html) [\[Stack Exchange\] SQL Server not Using Index](https://dba.stackexchange.com/questions/292020/sql-server-not-using-index) [\[SQL Espresso\] What's a Key Lookup](https://www.sqlshack.com/how-to-analyze-sql-execution-plan-graphical-components/) [\[SQL Shack\] How to Analyze SQL Execution Plan Graphical Components](https://www.sqlshack.com/how-to-analyze-sql-execution-plan-graphical-components/) [\[SQL Shack\] SQL Server Execution Plan Operators – Part 1](https://www.sqlshack.com/sql-server-execution-plan-operators-part-1/)